一口にプログラム言語と言っても、たくさんの種類があります。
ここでは、その中で、多くのプログラム言語に共通的な話をしていきます。
当面抽象的な話が続くので、理解しがたいかもしれませんが、理解出来なくても一回は目を通して、後日、もう一度この章を見直すことをお勧めします。
ここでは、その中で、多くのプログラム言語に共通的な話をしていきます。
当面抽象的な話が続くので、理解しがたいかもしれませんが、理解出来なくても一回は目を通して、後日、もう一度この章を見直すことをお勧めします。
変数と型
変数
多くのプログラミング言語は、変数という概念と型という概念を持ちます。変数は、プログラムで加工したり保存したりするデータを格納する場所です。
たいていのコンピュータ言語は英語に似た構文でプログラムを書きます。そして、変数にも名前を付けて区別します。名前はたいていは最初の一文字目をアルファベットで書いて、その後にアルファベットか数字が続いていく感じです。
(途中に_とか-とかの特殊文字も使えたりします。)
そこで、変数の名前も英語の単語を_でつなげるような形で、何を格納しているのか分かるようにしておくのが、後々の修正やメンテナンスを考えると都合が良いと思います。
組織でプログラムを作る場合は、変数の命名規則(変数の名前の付け方)も決められていることが多いです。
ただ、我々日本人にとっては、英単語でも読みにくくて、時間が経つと何を保存していたのがを忘れてしまいがちです。なので、変数名とその内容をプログラムの中に書いておくことと、Excelなどに一覧表として記録しておくと良いです。
型
多くのプログラム言語は、データの種類を区別するために、型と言うものを使います。ここではC#でも使う基本的な型を挙げておきます。
整数
計算が出来るデータです。コンピュータの世界では、一言で数値と言っても、大きく分けて整数と浮動小数点数の2種類の数があります。コンピュータの世界では、bitの列であるデータを、2進数の整数と見なして計算します。現在のパソコンで使われているCPUは4.byteのデータを数値と見なして計算できます。また、8byteのデータを数値と見なして計算できます。
4byteのデータは32個のbitからなるので、0000…0000 から 1111…1111までの情報を表現できます。これを正の2進数と見なせば0から4,294,967,295を表現できます。
また、2の補数という表現の考え方を使って、?2,147,483,648 から 2,147,483,647を表すと考えることもできる。
なので、一口に整数と言っても、符号付か符号なしか、また数値を何bitで表しているのかで、表現できる数値の範囲に差が出来ます。
C#ではこの整数に、下記の種類が存在します。
・byte -128 〜 127 の値を持つ符号付き8ビット整数
・ubyte 0 〜 256 の値を持つ符号なし8ビット整数
・short -32768 〜 32767 の値を持つ符号付き16ビット整数
・ushort 0 〜 65535 の値を持つ符号なし16ビット整数
・int -2147483648 〜 2147483647 の値を持つ符号付き32ビット整数
・uint 0 〜 4294967295 の値を持つ符号なし32ビット整数
・long -9223372036854775808 〜 9223372036854775807 の値を持つ符号付き64ビット整数
・ulong 0 〜 18446744073709551615 の値を持つ符号なし64ビット整数
・char 0 〜 65535 の値を持つ符号なし16ビット整数
ただし、char型はC#では整数型に分類されますが、他の整数とは、少し扱いが違います。詳細はC#の文法で確認ください。なお、この下の文字列の説明も参照してください。
また上記はC#の文法で整数型として定義されていますが、System名前空間で定義された構造体のエイリアスと言う面の性格も持っています。例えばintはSystem.Int32の、longはSystem.Int64のエイリアスです。(詳細は別途解説する予定です。)
浮動小数点数
コンピュータは何度も書いているように、bitの列で情報を表現する。なので、幾ら大量のbitを使っても、無限にはならないので実数を厳密に表現することは出来ない。ただ、計算をするうえで、ある一定の誤差の範囲で計算が出来れば、実務上は困らないケースが多い。そこで、コンピュータの世界では有限のbitで実数を近似する方法が使われてきた。それが浮動小数点数と言うもので、コンピュータの世界で標準的に使用されているのは、IEEEという規格を作成する団体で定められているreal*4、real*8で、C#ではそれぞれfloatとdoubleという型として呼ばれている。
(浮動小数点数の説明はここでは行わない。)
C#では、またdecimalという型を設け、有効桁数がfloatやdecimalよりも有効桁数が大きな数の計算に使用する型も用意されています。
文字列
1byteの情報で01000001をAという文字に、01000010をBという文字に対応させるという約束を決めることで、コンピュータの中で文字を扱うことが出来ます。この様に、1byteあれば、英大文字26文字、英小文字26文字、数字0〜9の10文字を表すことが可能です。しかし、漢字は1byteでは表せませんが、2byteあれば6万字程度は表現できます。
この様にbitの並びと文字の対応という約束事を文字コードと呼び、日本ではJISが規格として定めています。ただ、漢字については、中国でも使用されており、JIS以外でもいろいろなところで約束事を決めていたため、現在でも、様々な文字コードが使われています。
特にWEBの世界では、統一的な漢字コードと言うものは無く、サイトによって、使用されている文字コードが異なる状況が今でも続いています。
その中でも、MicrosoftとASCIIが作った、Shift-JIS(SJIS)というコードと、Unixの世界で策定されたEUC-JP(Extend Unix Code)、Unicode(UTF-8、UTF-16)と言った文字コードが良く使用されています。
C#では、この中のUnicode文字の列を文字列と呼んでいます。
文字コードと言う以外に、C#の文字列には、いろいろと特徴的な性格があります。C言語やC++言語を勉強したことがある人には、少し混乱するかもしれませんが、CやC++のchar型、char型配列、C++のstringとは別物と考えた方が良いと思います。
もっとも異なる点は、CyaC++にはcharの配列やstringは型ではない点です。これに対して、C#ではstring型として定義されています。更にC#のstringには終端文字という概念がありません。Cの文字配列やC++のstringは、文字の最後に00000000というビットパターンで表されるnull文字が付加されて、文字列の最後であることを示していました。しかし、この終端文字の扱いがきちんとできていないとプログラムの脆弱性を生み出していました。
C#では、終端文字に依存しないため、終端文字に伴う脆弱性は発生しません。(そもそも脆弱性って何と言う方はここは一旦置いておいて先に進み、後日で良いので情報セキュリティについて勉強してみてください。)
超基本的なアルゴリズム その1 - 順次処理
ここからはプログラムを考えるうえで、一番基本となる、アルゴリズムの考え方をまとめておきます。
ここではアルゴリズムの流れを、図で表現します。この図をフローチャートと呼びます。フロー(流れ)チャート(図)と言うことで、日本語では流れ図と呼ばれています。
ここでは、流れ図はアルゴリズムを表現するものとして使っていきます。
最初は順次処理です。
基本の考え方は、処理(機能)を並べて、一つのまとまった処理を行うことです。
プログラミングで一番重要なことは、すでにどんな処理が存在しているのか、使えるのかと言うことを把握することです。
コンピュータの言語だけ覚えても、実はほとんど何もできません。そのために、前述したライブラリにどういうものがあるのかを探して、今必要な機能を実現させるためには、何を組み合わせれば良いのかを探っていきます。
逆に言うと、これから実現する機能は、どんな機能があったら、実現できるのかを考えると、ライブラリを探す際の手掛かりになります。
なるべく順次処理できるように考えていくことです。
例えば朝の通勤を考えます。やりたいことは家から会社に移動するということです。
なので、
家から会社に移動する
という機能が何らかの形で実現できる手段を持っていれば、それで終了です。
そこで、少し細かくやるべきことをを分析します。最寄駅から会社近くの目的駅までは電車に乗ることが出来るとします。
すると、
1.家から最寄り駅まで移動する
2.目的駅に着く電車に乗る
3.目的駅で降りる
4.目的駅から会社まで移動する
と言った流れが想定できます。
細かく考えると、それぞれの部分をどうやって実行するのか(例えば、家から最寄り駅にはどうやって移動するのか)という実現方法はいろいろと考えなければならないかもしれませんが、だいたい上に書いた様な機能が実現できれば、順番に並べることで家から会社に移動することが出来ます。
アルゴリズムを考える上での、第一の出発点は処理を順番に並べると言うことです。
なんだ簡単なことじゃないかと思うかもしれませんが、機能を順番に並べてやりたいことを実現するという、この順次処理がアルゴリズムの基本的な考え方の中でも一番重要です。
ここではアルゴリズムの流れを、図で表現します。この図をフローチャートと呼びます。フロー(流れ)チャート(図)と言うことで、日本語では流れ図と呼ばれています。
ここでは、流れ図はアルゴリズムを表現するものとして使っていきます。
最初は順次処理です。
順次処理
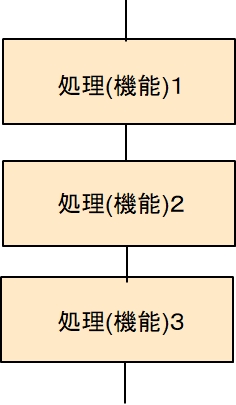
基本の考え方は、処理(機能)を並べて、一つのまとまった処理を行うことです。
プログラミングで一番重要なことは、すでにどんな処理が存在しているのか、使えるのかと言うことを把握することです。
コンピュータの言語だけ覚えても、実はほとんど何もできません。そのために、前述したライブラリにどういうものがあるのかを探して、今必要な機能を実現させるためには、何を組み合わせれば良いのかを探っていきます。
逆に言うと、これから実現する機能は、どんな機能があったら、実現できるのかを考えると、ライブラリを探す際の手掛かりになります。
なるべく順次処理できるように考えていくことです。
例えば朝の通勤を考えます。やりたいことは家から会社に移動するということです。
なので、
家から会社に移動する
という機能が何らかの形で実現できる手段を持っていれば、それで終了です。
そこで、少し細かくやるべきことをを分析します。最寄駅から会社近くの目的駅までは電車に乗ることが出来るとします。
すると、
1.家から最寄り駅まで移動する
2.目的駅に着く電車に乗る
3.目的駅で降りる
4.目的駅から会社まで移動する
と言った流れが想定できます。
細かく考えると、それぞれの部分をどうやって実行するのか(例えば、家から最寄り駅にはどうやって移動するのか)という実現方法はいろいろと考えなければならないかもしれませんが、だいたい上に書いた様な機能が実現できれば、順番に並べることで家から会社に移動することが出来ます。
アルゴリズムを考える上での、第一の出発点は処理を順番に並べると言うことです。
なんだ簡単なことじゃないかと思うかもしれませんが、機能を順番に並べてやりたいことを実現するという、この順次処理がアルゴリズムの基本的な考え方の中でも一番重要です。
超基本的なアルゴリズム その2 - 判断
次にアルゴリズムで基本的な考え方が判断もしくは選択です。
判断とは条件を考えて、条件が成立している場合と不成立の場合に訳て処理を行う考え方です。
まずは条件が成立した場合だけ処理をするパターンです。
条件が成立している場合に、処理を行うものです。
ただ条件をプログラム言語で表す方法は、プログラム言語によって様々です。同じような表現をしていても言語によってはまるっきり別の意味になったりもしますので注意してください。
また、多くの言語で条件は論理式として与えられて、その結果はTrueかFalseの値を取ります。
なので、上の場合は、Trueなら処理(機能)を行うということになります。
ここで混乱する人が出てくるので、最初に伝えておくと、論理式には反転(NOT)という操作が出来ます。
条件の反転はNOT(条件)です。
そうすると、下の図は、上の図と同じことを表現します。
言葉にすると、
NOT(条件)が不成立の場合に、処理を行う
と言うことです。
また、図としては、こう書いても同じことを表します。
もう混乱していませんか?
条件の成立・不成立を間違えると処理はやりたいこととは違ってしまいます。
次の判断 - その2のところで書きますが、システムのバグと言われるものが発生する大きな箇所が、この判断の条件の部分の誤りです。
条件が成立した場合は処理(機能)1を実施し、不成立の場合は処理(機能)2を実施するというものです。
コンピュータ言語的に書くと
if (条件)
then
処理(機能)1
else
処理(機能)2
となります。
同様に、判断 - その1は
if (条件)
then
処理(機能)1
と書けます。
条件の反転は、ここではNOT(条件)と書くことにしましょう。すると上は、
if NOT(条件)
then
処理(機能)2
else
処理(機能)1
と書いても同じということが分かりますか。
なので、判断 - その1は
if NOT(条件)
then
何もしない
else
処理(機能)1
となります。
【応用例題】
条件Aが成立していた時は、( 条件Bが成立していた時 処理(機能)1を行い、条件Bが不成立の時は、処理(機能)2を行う )
条件A不成立の時は、( 条件Cが成立していた時 処理(機能)3を行い、条件Bが不成立の時は、処理(機能)4を行う )
はどんな図になりますか
【解答】
この問題では、条件Aと条件B、Cと2階層ですが、条件が数階層どころか、もっと多い場合もあります。
そうすると、分岐する可能性も多くなって、すべての条件が正しく判断で来ているか、すべての処理が、テストできているかコントロール出来ていない場合もあります。そうすると、判断に誤りがあったり、テスト漏れが出てくるため、実際にシステムを使う際に、トラブルが発生していわゆる世間でいう「バグ」が発生します。
判断とは条件を考えて、条件が成立している場合と不成立の場合に訳て処理を行う考え方です。
まずは条件が成立した場合だけ処理をするパターンです。
判断 - その1
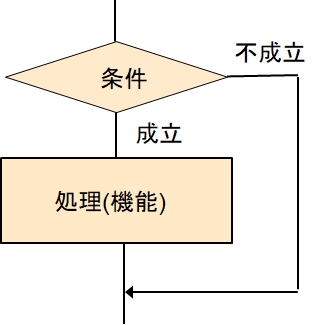
条件が成立している場合に、処理を行うものです。
ただ条件をプログラム言語で表す方法は、プログラム言語によって様々です。同じような表現をしていても言語によってはまるっきり別の意味になったりもしますので注意してください。
また、多くの言語で条件は論理式として与えられて、その結果はTrueかFalseの値を取ります。
なので、上の場合は、Trueなら処理(機能)を行うということになります。
ここで混乱する人が出てくるので、最初に伝えておくと、論理式には反転(NOT)という操作が出来ます。
条件の反転はNOT(条件)です。
そうすると、下の図は、上の図と同じことを表現します。
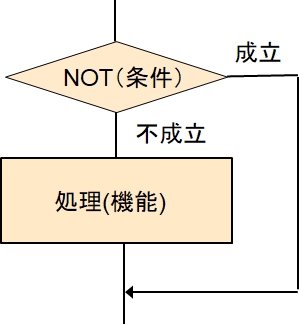
言葉にすると、
NOT(条件)が不成立の場合に、処理を行う
と言うことです。
また、図としては、こう書いても同じことを表します。
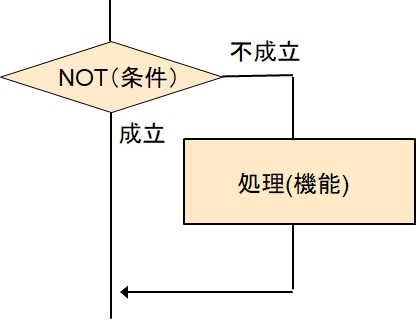
もう混乱していませんか?
条件の成立・不成立を間違えると処理はやりたいこととは違ってしまいます。
次の判断 - その2のところで書きますが、システムのバグと言われるものが発生する大きな箇所が、この判断の条件の部分の誤りです。
判断 - その2
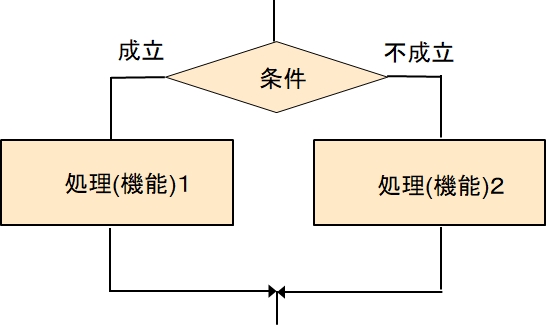
条件が成立した場合は処理(機能)1を実施し、不成立の場合は処理(機能)2を実施するというものです。
コンピュータ言語的に書くと
if (条件)
then
処理(機能)1
else
処理(機能)2
となります。
同様に、判断 - その1は
if (条件)
then
処理(機能)1
と書けます。
条件の反転は、ここではNOT(条件)と書くことにしましょう。すると上は、
if NOT(条件)
then
処理(機能)2
else
処理(機能)1
と書いても同じということが分かりますか。
なので、判断 - その1は
if NOT(条件)
then
何もしない
else
処理(機能)1
となります。
【応用例題】
条件Aが成立していた時は、( 条件Bが成立していた時 処理(機能)1を行い、条件Bが不成立の時は、処理(機能)2を行う )
条件A不成立の時は、( 条件Cが成立していた時 処理(機能)3を行い、条件Bが不成立の時は、処理(機能)4を行う )
はどんな図になりますか
【解答】
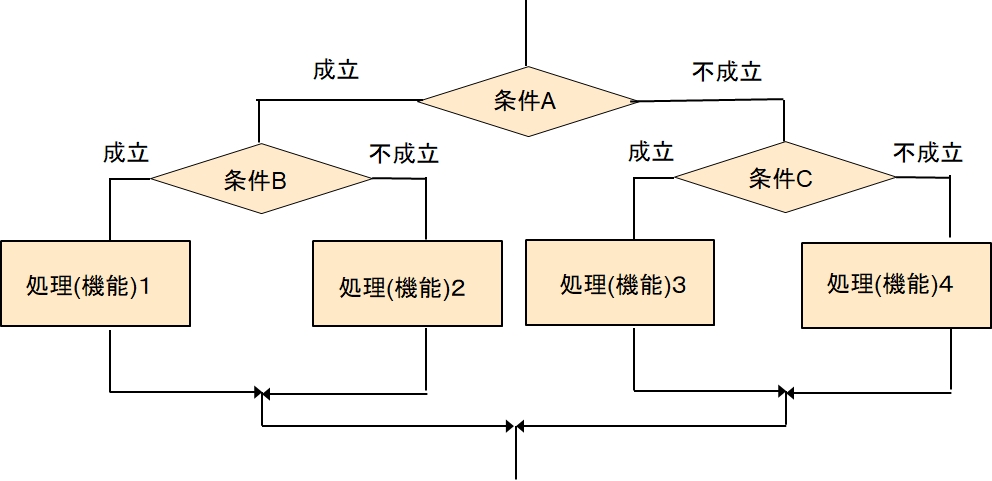
この問題では、条件Aと条件B、Cと2階層ですが、条件が数階層どころか、もっと多い場合もあります。
そうすると、分岐する可能性も多くなって、すべての条件が正しく判断で来ているか、すべての処理が、テストできているかコントロール出来ていない場合もあります。そうすると、判断に誤りがあったり、テスト漏れが出てくるため、実際にシステムを使う際に、トラブルが発生していわゆる世間でいう「バグ」が発生します。
超基本的なアルゴリズム その3 - 分岐
基本的な考え方に入れていますが、この分岐は、その2 - 判断の応用系です。
変数の値によって、それぞれ該当する処理(機能)を実施するというものです。
現在のコンピュータ言語では、switchで分岐を表すことが多いです。そして、分岐する変数の値をcaseで示します。
switch 変数
case 値1
処理(機能)1
case 値2
処理(機能)2
case 値3
処理(機能)3
default
処理(機能)4
言語によっては、上の様な記述をした場合に、フローチャートとは異なり、それぞれの処理をすました後に、そのまま次の処理を続けるという仕様の言語があります。
図にするとこんな感じでしょうか
そこで、それぞれの処理を実施したら、switchから抜け出る様にするために、次のような記述をするものもあります。
switch 変数
case 値1
処理(機能)1
break
case 値2
処理(機能)2
break
case 値3
処理(機能)3
break
default
処理(機能)4
ここでbreakはswitchの処理から抜けることを明示的に示すものです。C#の分岐処理もこのタイプになります。
因みに、最初に分岐は判断の応用系だと書きました。昔のコンピュータ言語であるCobolやFortranには分岐という概念は無く、このアルゴリズムを実現するには、判断を組み合わせて実現していました。
例えば、判断であるifを使うと、こんな感じになります。
if (変数が値1に等しい)
then
処理(機能)1
else if (変数が値2に等しい)
then
処理(機能)2
else if (変数が値3に等しい)
then
処理(機能)3
else
処理(機能)4
アルゴリズムは1つではないと書きましたが、同じアルゴリズムを表現する方法も1つではありません。
分岐
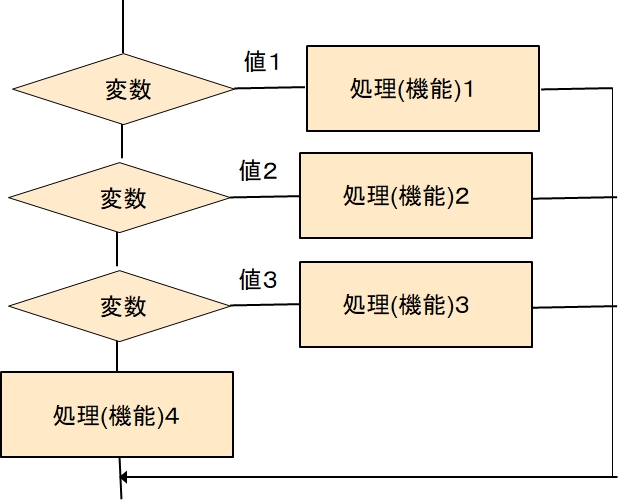
変数の値によって、それぞれ該当する処理(機能)を実施するというものです。
現在のコンピュータ言語では、switchで分岐を表すことが多いです。そして、分岐する変数の値をcaseで示します。
switch 変数
case 値1
処理(機能)1
case 値2
処理(機能)2
case 値3
処理(機能)3
default
処理(機能)4
言語によっては、上の様な記述をした場合に、フローチャートとは異なり、それぞれの処理をすました後に、そのまま次の処理を続けるという仕様の言語があります。
図にするとこんな感じでしょうか
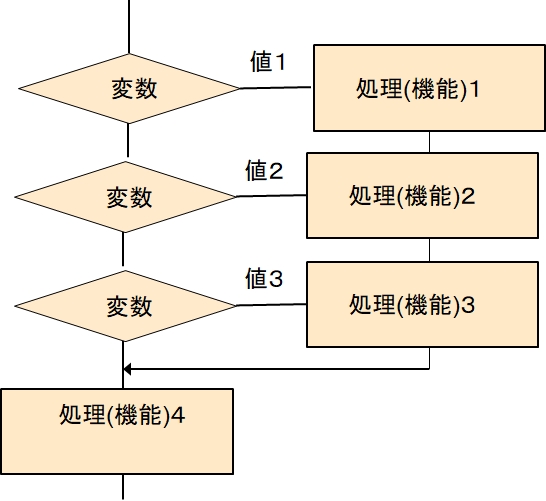
そこで、それぞれの処理を実施したら、switchから抜け出る様にするために、次のような記述をするものもあります。
switch 変数
case 値1
処理(機能)1
break
case 値2
処理(機能)2
break
case 値3
処理(機能)3
break
default
処理(機能)4
ここでbreakはswitchの処理から抜けることを明示的に示すものです。C#の分岐処理もこのタイプになります。
因みに、最初に分岐は判断の応用系だと書きました。昔のコンピュータ言語であるCobolやFortranには分岐という概念は無く、このアルゴリズムを実現するには、判断を組み合わせて実現していました。
例えば、判断であるifを使うと、こんな感じになります。
if (変数が値1に等しい)
then
処理(機能)1
else if (変数が値2に等しい)
then
処理(機能)2
else if (変数が値3に等しい)
then
処理(機能)3
else
処理(機能)4
アルゴリズムは1つではないと書きましたが、同じアルゴリズムを表現する方法も1つではありません。
超基本的なアルゴリズム その4 - 反復
いよいよ超基本的なアルゴリズムの考え方の最後の反復になります。
同じ処理を何度も繰り返すものです。ただ、ずっと繰り返すと、終わりません。コンピュータの処理では通常どこかで終了します。
そこで、繰り返す前に終了するかどうか判断するものと、1度は処理を実行して終了するかどうか判断するものの、大きく2つの流れがあります。
(処理の途中で終了するものも流れとしてはありますが、上の2つがあれば途中で終了するパターンも実現できます。)
順番に見て行きます。
最初に条件を評価します。
条件が成立していれば、処理(機能)を実施して、最初にもどります。(これで処理が反復します。)
もし条件が不成立ならば繰り返しを終了します。
一行で書くと、条件が成立している間、処理(機能)を実施すると言うことになります。
そこで、上の一行を英語の様に買いて、
while (条件) do
処理(機能)
という感じに書きます。(コンピュータ言語での表現は、それぞれの言語で違いがあるので、仕様を確かめてください。)
処理(機能)を実施した後に条件を評価します。
条件が成立しなければ、再度、上に戻ります。(これで処理が反復します)
条件が成立したら処理を終了します。
一行で書くと、処理(機能)を条件が成立するまで実施する
そこで、そこで、上の一行を英語の様に買いて、
do
処理(機能)
until (条件)
という感じに書きます。(何度も書きますが、コンピュータ言語での表現は、それぞれの言語で違いがあるので、仕様を確かめてください。)
一応、途中で首領を判断する流れも見てみます。
これは、コンピュータ言語によっては、このアルゴリズムを表現できるものもあります。
例えば、こんな形に書きます。
loop
処理(機能)1
if (条件) break
処理(機能)2
loopend
loopとloopendの間を繰り返し続けます。
そこで、途中で条件を評価して、成立したら、breakでloopを抜けます。
ただ、直接掛けなくても、この流れは、次のように考えることが出来ます。
つまり、
処理(機能)1
while NOT(条件) do
処理(機能)2
処理(機能)1
こんな感じで、反復 - その1を使って表現できます。
同じ処理を何度も繰り返すものです。ただ、ずっと繰り返すと、終わりません。コンピュータの処理では通常どこかで終了します。
そこで、繰り返す前に終了するかどうか判断するものと、1度は処理を実行して終了するかどうか判断するものの、大きく2つの流れがあります。
(処理の途中で終了するものも流れとしてはありますが、上の2つがあれば途中で終了するパターンも実現できます。)
順番に見て行きます。
反復 - その1 最初に終了を判断
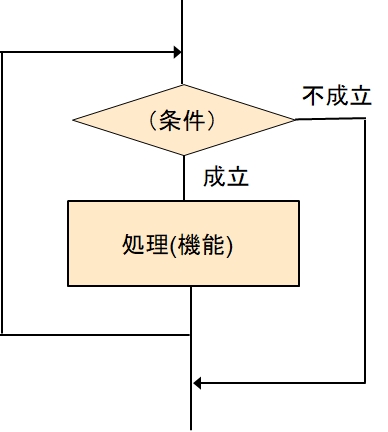
最初に条件を評価します。
条件が成立していれば、処理(機能)を実施して、最初にもどります。(これで処理が反復します。)
もし条件が不成立ならば繰り返しを終了します。
一行で書くと、条件が成立している間、処理(機能)を実施すると言うことになります。
そこで、上の一行を英語の様に買いて、
while (条件) do
処理(機能)
という感じに書きます。(コンピュータ言語での表現は、それぞれの言語で違いがあるので、仕様を確かめてください。)
反復 - その2 最後に終了を判断
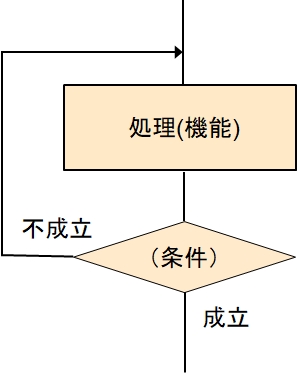
処理(機能)を実施した後に条件を評価します。
条件が成立しなければ、再度、上に戻ります。(これで処理が反復します)
条件が成立したら処理を終了します。
一行で書くと、処理(機能)を条件が成立するまで実施する
そこで、そこで、上の一行を英語の様に買いて、
do
処理(機能)
until (条件)
という感じに書きます。(何度も書きますが、コンピュータ言語での表現は、それぞれの言語で違いがあるので、仕様を確かめてください。)
一応、途中で首領を判断する流れも見てみます。
反復 - その3 途中で終了を判断
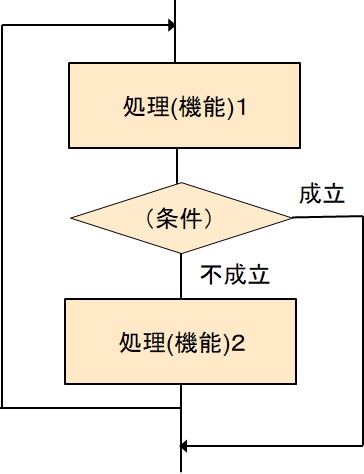
これは、コンピュータ言語によっては、このアルゴリズムを表現できるものもあります。
例えば、こんな形に書きます。
loop
処理(機能)1
if (条件) break
処理(機能)2
loopend
loopとloopendの間を繰り返し続けます。
そこで、途中で条件を評価して、成立したら、breakでloopを抜けます。
ただ、直接掛けなくても、この流れは、次のように考えることが出来ます。
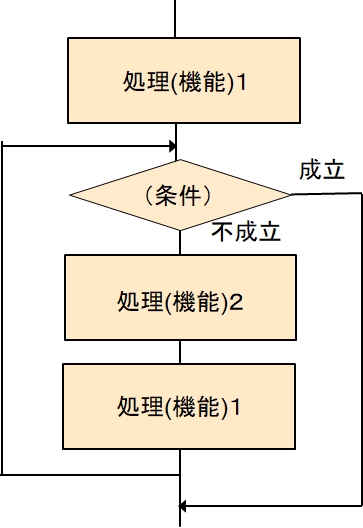
つまり、
処理(機能)1
while NOT(条件) do
処理(機能)2
処理(機能)1
こんな感じで、反復 - その1を使って表現できます。
雑談 - システムのトラブルとか運用とか情報セキュリティの話
ここまでで、超基本的なアルゴリズムの考え方を説明してきました。
システムは、実現したい機能のアルゴリズムを分析して、より小さなアルゴリズムに分解して、最終的にこれらのパターンを組み合わせて、コンピュータ言語で記述していきます。
逆に言えば、これらのパターンしかコンピュータ言語では表現できません。この単純なパターンを組み合わせることで、多岐にわたる処理を実現しているのです。
何度も書いているように、単純な組み合わせで大きな処理を組み立てるため、そのステップはシステムによっては、何万ステップどころか何十万、何百万のステップが必要になります。
そして、その組み合わせの順番を一つでも間違ええると、本来システムに期待している動きをしてくれません。
ただ、システムは、通常小さなシステムの寄合所帯になっています。また、それぞれのシステムが、複数の機能を実現しているものになります。なので、たいていは99%はテストが出来ているので、借りに誤りがあっても、通常の使い方では表に出て来ず問題にならないのです。
ただ、見落とされているケースは普段は表に出てこないのだけれども、表に現れる時は、えてして、処理が立て込んでいる様な特殊な状態で発生して大きな問題につながるケースが多いので、ニュースになったりします。
99%は評価されず、テストされていない1%の見落としで酷評されるのはシステム屋さんの宿命でしょう。
開発とは異なりますが、ネットワークやシステムのインフラを担う人たちは、普段トラブルにならない様にメンテナンスに勤めています。しかし、きちんとメンテナンスをしているがために、経営層からはトラブルが無いから人手を減らしても大丈夫だろうという評価がされたりします。そして人手が減らされた結果、大きなトラブルが発生するというのは、実は表に現れていませんが、システムに無知な日本の会社では日常茶飯事に発生していることです。
要はリスク管理にお金が必要なのに、トラブル(クライシス)が発生していないからと、リスク管理にお金を使わない訳です。これは例えば、情報セキュリティに当てはめれば理解できると思います。
日本ではおそらく殆どの会社で、ハッキング等が発生しない限り、ウィルス対策ソフト位は導入しますが、それ以上の対策にはお金を支払ってくれません。
情報セキュリティ対策は一種の保険ですが、クライシスが発生した際の復旧や対応費用などの金額を被害を受けたたいていの会社で公開していないので、保険にどの位掛けたら良いのかが実は見積もりされていないのです。
結局、1部上場企業を含めて日本の会社はリスク管理が出来ていないと言っても過言ではありません。強いて言えばある程度きちんと行っているのは、金融庁の管轄の金融機関や保険会社位です。(これ以上は余り書きませんが)
システムは、実現したい機能のアルゴリズムを分析して、より小さなアルゴリズムに分解して、最終的にこれらのパターンを組み合わせて、コンピュータ言語で記述していきます。
逆に言えば、これらのパターンしかコンピュータ言語では表現できません。この単純なパターンを組み合わせることで、多岐にわたる処理を実現しているのです。
何度も書いているように、単純な組み合わせで大きな処理を組み立てるため、そのステップはシステムによっては、何万ステップどころか何十万、何百万のステップが必要になります。
そして、その組み合わせの順番を一つでも間違ええると、本来システムに期待している動きをしてくれません。
ただ、システムは、通常小さなシステムの寄合所帯になっています。また、それぞれのシステムが、複数の機能を実現しているものになります。なので、たいていは99%はテストが出来ているので、借りに誤りがあっても、通常の使い方では表に出て来ず問題にならないのです。
ただ、見落とされているケースは普段は表に出てこないのだけれども、表に現れる時は、えてして、処理が立て込んでいる様な特殊な状態で発生して大きな問題につながるケースが多いので、ニュースになったりします。
99%は評価されず、テストされていない1%の見落としで酷評されるのはシステム屋さんの宿命でしょう。
開発とは異なりますが、ネットワークやシステムのインフラを担う人たちは、普段トラブルにならない様にメンテナンスに勤めています。しかし、きちんとメンテナンスをしているがために、経営層からはトラブルが無いから人手を減らしても大丈夫だろうという評価がされたりします。そして人手が減らされた結果、大きなトラブルが発生するというのは、実は表に現れていませんが、システムに無知な日本の会社では日常茶飯事に発生していることです。
要はリスク管理にお金が必要なのに、トラブル(クライシス)が発生していないからと、リスク管理にお金を使わない訳です。これは例えば、情報セキュリティに当てはめれば理解できると思います。
日本ではおそらく殆どの会社で、ハッキング等が発生しない限り、ウィルス対策ソフト位は導入しますが、それ以上の対策にはお金を支払ってくれません。
情報セキュリティ対策は一種の保険ですが、クライシスが発生した際の復旧や対応費用などの金額を被害を受けたたいていの会社で公開していないので、保険にどの位掛けたら良いのかが実は見積もりされていないのです。
結局、1部上場企業を含めて日本の会社はリスク管理が出来ていないと言っても過言ではありません。強いて言えばある程度きちんと行っているのは、金融庁の管轄の金融機関や保険会社位です。(これ以上は余り書きませんが)